TITLE
Classification of documents by using Naive Bayes
ABSTRACT
This project is to identify the class of the documents, based on the documents used for training. To be clear, few documents and the corresponding class of document will be given. Now, by using Multinomial Naive Bayes algorithm given documents are analyzed. Navie Bayes uses the conditional probability of Bayes theorem. When test document is given multinomial algorithm analyzes every word in the text document in perspective to all classes and assigns a score. Finally, the class with more score is the class of the testing document.
RELATED DOMAIN OF STUDY
Bayes Theorem helps us to find the probability of an event to occur, based on conditions related to the event in advance. For example, if a disease is related to geographical location, then using Bayes theorem, a person’s geographical location can be used to more accurately assess the probability that they have the disease, compared to the assessment of the probability of disease made without knowledge of the person’s location.
Multinomial Naive Bayes uses Bayes Theorem to find the probability of the document to be in particular class or category. And this is based on analysis of the previous document set used for training the algorithm.
DATA SOURCES
Data Sources for my project would be, documents with some text in it. I need to have two sets of documents one with categorized documents for training the algorithm and other with uncategorized documents for testing.
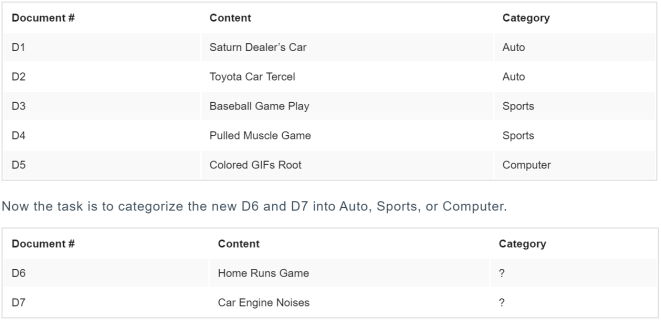
For example, have a look at my sample dataset